
昨天通過一番資料分析,確認主辦方提供的 17,307 筆 training data 中,有 12,873 筆完全一模一樣的 essay 內容出現在 PERSUADE 2.0 Corpus 這個公開資料集裡面;另外找到有兩筆 data 有修改一些內文,例如去掉 PII(Personal Identity Information),但其實整體內容都能在 PERSUADE 2.0 Corpus 找到包含 label 也相同的資料。這意味我們可以利用 PERSUADE 2.0 Corpus 有提到但本次比賽沒有提供的一些 feature ,包含 Prompt Name, Prompt Text 等等來開發模型。
至於剩下的 4432 筆 data 都沒辦法在 PERSUADE 2.0 Corpus 找到相似、對應的 sample。
因此根據上面的觀察,我們可以初步得到一個結論: Training data 大部分都取自 PERSUADE 2.0 Corpus,但其中有一小部分的 data 來自另外一個 source。
接下來我們昨天留下的問題是:testing data 是否也和 training data 一樣大部分來自 PERSUADE 2.0 Corpus?
有三種可能:
1. 測試資料完全來自 PERSUADE 2.0 Corpus
2. 測試資料部分來自 PERSUADE 2.0 Corpus
3. 測試資料完全不來自 PERSUADE 2.0 Corpus,和它一點關係都沒有
由於 testing data 是不可見的,使得直接分析 testing data 的文字變得不可能,我們只能設計一些間接的方法來驗證我們的假設。
為了驗證這件事情,首先我們可以先提交某個基於單一、簡單的規則的simple baseline(例如: 每一題都盲猜答案是 3);然後再提交一個透過比對 testing data 與 PERSUADE Corpus 的 essay 內容,如果有內容一樣的話,就輸出該筆資料的 label 的方法。我們在這邊稱這這種方式為"Retrieval-based method"。
接下來透過觀察這兩個方法在 Leaderboard 得到的分數,應該就可以告訴我們一些關於 testing data 的秘密。
假設 test data 也跟 train data 一樣有大量來自 PERSUADE 2.0 的 data,那我們可以預期 Retrieval-based 的方法在 leaderboard 上的分數應該要顯著比 baseline 高許多。
假設學生繳交的 essays 字數越多,越有可能得到較高的分數。因此初步的簡單方案是先將 training data 的文字按照字數分組,並計算每一組的分數眾數,再應用累積最大值函數(因為假設分數會隨著字數增加而遞增),就可以得到 training data 中每一個字數區間的代表分數。
如果有點不知道上面在說什麼的話,我們直接上 code 跟著做做看:
# 取得每一篇 essay 的字數長度 (去掉空白符號和 e)
# 字數以 50 個字為單位分成多個 bucket
// 取得 train/test 的 essay 內容,並去掉空白和大小寫 e (這邊猜測 e 是英文字最常見的字母,去掉可能可以簡化計算)
// 將 essay 的總字數除以50,並將結果存到 length 這個 column 裡面(將總字母數以50為區間分組)
train["length"] = train.full_text.str.replace("[Ee\s]", "", regex=True).str.len() // 50
test["length"] = test.full_text.str.replace("[Ee\s]", "", regex=True).str.len() // 50
# Get modal score per length bin
# assume monotone-increasing
// 1. 將 train data 用 langth 做分組
// 2. 並計算該組的分數眾數
// 3. 再填補缺失值
// 4. 設定最小值為1(本次dataset的score共有6個級距:1~6)
// 5. 最後應用累積最大值函數(假設分數隨長度單調增加)。
modes = (train
.groupby("length")
.score
.agg(lambda s: s.value_counts().keys()[0])
.sort_index()
.reindex(range(0, 200))
.fillna(0)
.clip(lower=1)
.cummax()
.astype(int))
按照上面步驟處理好資料後,可以把 train data 的 essay 長度和 score 分數畫出下面的累積分數圖: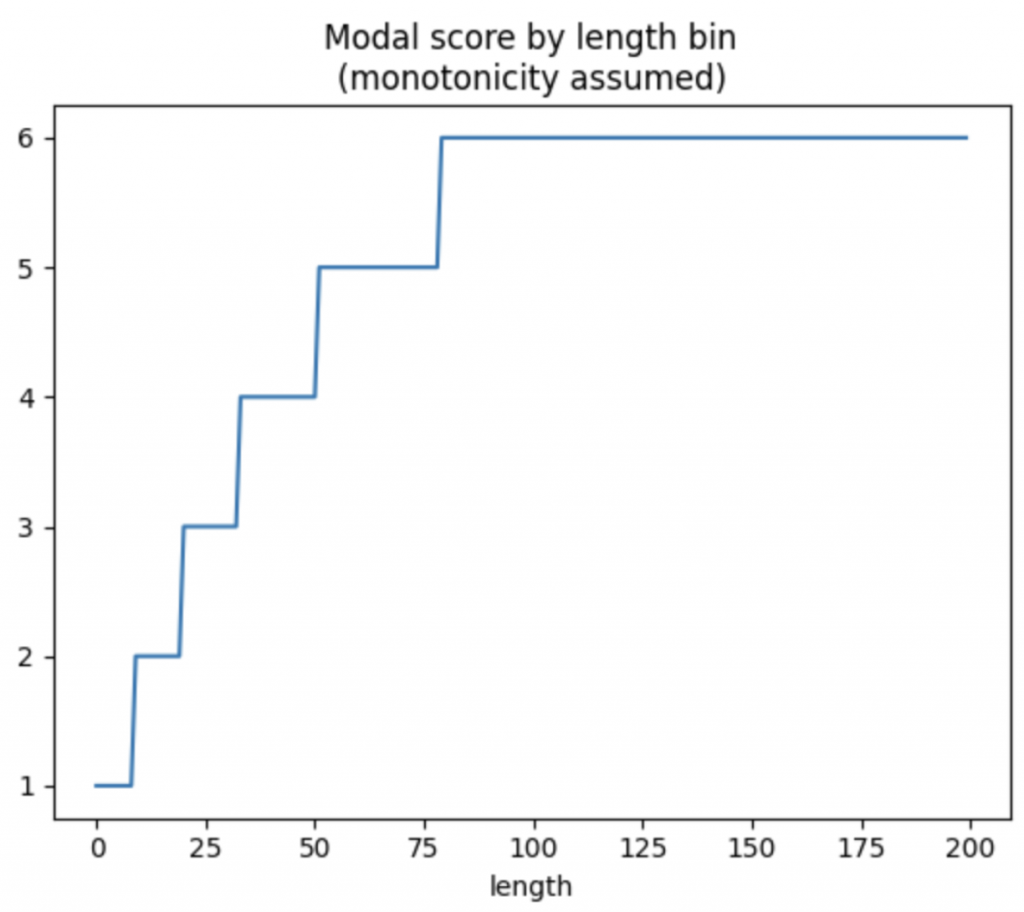
接下來把 test data 的 essay 也根據其文字長度的區間,應用到前面從 train data 找到的眾數分數,來當作預測出的 test data 的分數。
baseline = test.length.map(modes).rename("score")
baseline.to_csv("submission.csv")
好了,接下來我們就傳出這份熱騰騰的 "submission.csv",用這份檔案計算出的成績當作我們 simple baseline 的分數。(完整code請參考1)
🔎 Finding: simple baseline 在 leaderboard 的 Public Score 是 0.7034 分。
(註: 也許你會覺得這邊做法有點複雜,其實也可以不管三七二十一,直接盲猜每一題的分數都是 3 分也可以,反正只是為了和後面的方法比較而已,這樣更簡單!)
有了 simple baseline 做比較之後,就可以來試試看使用 Persuade 2.0 會不會提升 performance。根據 performance 是否有上升來驗證到底 testing data 是否含有 persuade 的內容。
首先,為了做 retrieve(檢索) ,要先把 testing data 和 Persuade 的文字都先轉成向量,這樣就可以透過計算向量的距離來 mapping 和該筆 testing data 最相似的 Persuade essay。
這邊為了簡化計算,使用 CountVectorizer 來產生 embedding:
// CuPy (通常導入為 cp) 是一個開源的數組庫,主要用於 CUDA GPU 計算。它的設計目標是成為 NumPy 的 GPU 加速替代品。
import cupy as cp
from sklearn.feature_extraction.text import CountVectorizer
model = CountVectorizer(stop_words='english',max_features=1024)
p_embed = model.fit_transform(persuade.full_text.values)
// 將 p_embed 放到 GPU 計算
p_embed = cp.array(p_embed.toarray())
// 將 p_embed 做 p2 normalization
norm = cp.sqrt( cp.sum(p_embed*p_embed,axis=1, keepdims=True) )
p_embed = p_embed / norm
// 將 test data 中的 essay full_text 也轉成 embedding
test_embed = model.transform(test.full_text.values)
test_embed = cp.array(test_embed.toarray())
norm = cp.sqrt( cp.sum(test_embed*test_embed,axis=1, keepdims=True) )
test_embed = test_embed / norm
有了 embedding 之後就可以計算兩者的相似度:
// 為每一筆 test data 找到和其 cosine similarity 最高的 PErsuade text
top1 = cp.dot(p_embed, test_embed.T)
top1 = cp.argmax(top1,axis=0)
為了和 simple baseline 比較,我們先把前面 baseline 根據長度分組的結果 merge 進來。
如果用 cosine similarity 找到的最高分的 Persuade 2.0 essay 和該筆 test data 的 normalized levenshtein distance < 0.1 ,我們就非常有信心這筆 test data 的 label 應該會和找到的這個 Persuade text 一樣,如此就可以用它的 label 替換掉 simple baseline 計算出的 label ,並預期這樣做之後, perfornamce 應該會比 simple baseline 更好。
// 先和 baseline 合併,為了以防萬一有缺失職,使用平均的分數:3 來填補。
test = test.merge(baseline, on='essay_id', how='left').fillna(3)
// 把和每一筆 test data cosine similarity 最高的的那一筆 Persuade data 的 full_text 以及它的原始分數放進來
for k in range(len(test)):
test.loc[k,'full_text_p'] = persuade.loc[top1[k].item(),'full_text']
test.loc[k,'score_p'] = persuade.loc[top1[k].item(),'holistic_essay_score']
// 計算每一筆 test data 和 mapping 到的那筆 persuade text 的 levenshtein distance
test = test.apply(levenshtein_distance,axis=1)
// 如果算出來的 levenshtein_distance <0.1,就用 score_p(persuade text 原始的 label) 來替換掉 baseline 計算出的分數
test.loc[test.lev<MATCH_THRESHOLD,'score'] = test.loc[test.lev<MATCH_THRESHOLD,'score_p']
(上方完整代碼請見2)
🔎 Finding: 最後提交的分數和 simple baseline 一樣,都是 0.7034。
懸著的心終於死了QQ,這個結果代表主辦單位那邊的測試資料,應該大部分都不從 Persuade 2.0 Corpus 出的!
今天透過設計 simple baseline 以及 retrival-based method 探討隱藏測試資料的身世之謎等內容,先在這邊告一個段落了~
雖然無法在 Persuade 2.0 Corpus 找到完全一模一樣的測試資料,但也許他們還有千絲萬縷的關係和共同點,等待我們去挖掘呦!
明天開始會帶大家一起進入 NLP 相關 data 競賽的一些基本操作,包含起手式 Topic Modeling, 各個 feature 和 label 的 correlation analysis 等等;我們也會對測試資料有更多猜測和假設,等著我們設計方法來驗證~
謝謝讀到最後的你,希望你會覺得有趣!
如果喜歡這系列,別忘了按下訂閱,才不會錯過最新更新,也可以按讚給我鼓勵呦!
希望今年可以堅持完賽!
如果有任何回饋和建議,歡迎在留言區和我說✨✨
(Kaggle - Learning Agency Lab - Automated Essay Scoring 2.0 解法分享系列)

 iThome鐵人賽
iThome鐵人賽